
It’s been a discussion since long how Google determines different file types before indexing them into Google search.
Google Converts PDF into HTML for Indexing
Now, Googler John Mueller has come up with an explanation to this question. During a conversation on Twitter, he reveled a bit about PDFs in the Google search results and how Google handles them.
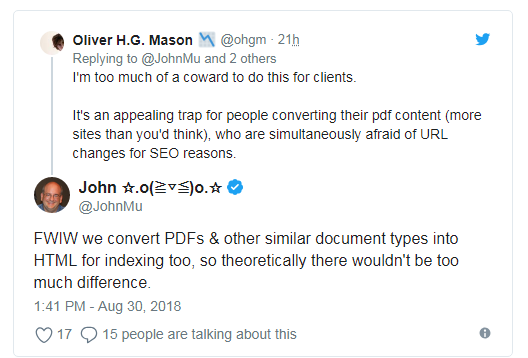
John Mueller said during the conversation that Google has an inbuilt mechanism to automatically convert PDFs and similar document types into HTML format to serve various purposes including indexing and ranking.
For SEO People who have been in the optimization of PDF files, this is something they already know. Google, since long, has converted PDFs into HTML and included a link to the HTML version directly in the search results. The problem is that in case of a large file Google doesn’t convert the entire PDF document into HTML. This results in a part of content within the PDF that is just simply not indexed because of the PDF size.
PDF files rank very well for the types of queries where someone is looking for something like a search for a manual in PDF format.
Along with the PDFs, Google converts .doc documents (such as Word documents), .xls (spreadsheets) and other similar non-HTML content types to HTML for indexing and ranking.

- AI’s Impact on Personalization, Analytics, and Retention in Gaming - April 12, 2024
- The Marketer’s Marathon: Long-Distance Strategies for Sustained Traffic Growth - March 29, 2024
- What Is MagSafe for iPhone? A Quick Guide - March 18, 2024



